The Economics of AI Training and Inference: How DeepSeek Broke the Cost Curve

AI progress has been fueled by larger models and more powerful infrastructure, but at an unsustainable price. Over the past decade, AI training and inference costs have grown exponentially, making efficiency one of the most critical challenges in AI development today.
Example: In 2018, training GPT-2 cost a few hundred thousand dollars. By 2023, training GPT-4 is estimated to have exceeded $100 million.
This article explores:
✅ The rising costs of AI training and inference
✅ How AI firms optimize architectures to reduce costs
✅ MoE’s role in making AI more efficient
✅ The future of AI cost efficiency and sustainability
2. The Cost of AI Training: Breaking Down the Numbers
AI training costs depend on compute, energy, and storage. While proprietary models don’t disclose exact costs, we can estimate them using public benchmarks and infrastructure pricing.
2.1 Estimated Training Costs for Major AI Models
Model
Estimated Training Cost (USD)
GPUs Used
Training Time
Parameter Count
GPT-4 (OpenAI)
~$100M-$200M
20,000+ A100s
Several months
~1.7T (estimated)
Claude 3 (Anthropic)
~$100M+
Likely ~10,000+ A100s
Several months
Estimated ~1.5T
Gemini 2.0 (Google)
~$200M-$300M
Custom TPUs
Unknown
~2.5T (estimated)
DeepSeek R1
~$50M-$80M
MoE-optimized GPUs
Faster due to sparse computation
1.8T (total, sparse)
Mistral 7B
~$2M-$5M
Minimal GPU requirements
Weeks
7B
2.2 What Drives AI Training Costs?
🔹 Compute & GPU Expenses:
- High-end GPUs (e.g., Nvidia H100, A100) cost $30,000+ each.
- AI models require tens of thousands of GPUs or TPUs.
🔹 Energy Consumption:
- AI training consumes huge amounts of electricity—GPT-4 training was estimated to use as much power as 180,000 U.S. homes in a month.
🔹 Data Processing & Storage:
- Large-scale datasets require months of preprocessing before training begins.
🔹 Model Architecture:
- Dense models activate all parameters per query, making them expensive to scale.
3. The Economics of AI Inference: The Real Business Challenge
Training costs are one-time expenses, but inference costs persist indefinitely—every user query, chatbot interaction, or API call incurs ongoing computational costs.
3.1 Public AI Inference Costs (API Pricing & Estimates)
Model
Estimated Inference Cost ($ per 1M tokens)
VRAM Requirement
Cost Efficiency
GPT-4
~$13.50
48GB+ VRAM
High cost per query
Claude 3
~$8.00
Likely 40GB+ VRAM
Moderate
Gemini 2.0
~$3.00
TPU-optimized
More efficient than GPT-4
DeepSeek R1
~$0.50
24GB VRAM
Most cost-effective
Mistral 7B
~$0.10
Minimal (fits on consumer GPUs)
Ultra-low cost
3.2 What Makes AI Inference Expensive?
🔹 Hardware Requirements:
- Large models require high-end GPUs with 48GB+ VRAM.
- Cloud providers charge per GPU-hour, making inference a significant ongoing expense.
🔹 Latency & Efficiency Challenges:
- Running AI models in real-time increases cloud computing costs.
- Models like GPT-4 require multiple GPUs per query, making them less scalable.
🔹 Memory Bottlenecks:
- AI models with longer context windows (e.g., Gemini 2.0 at 2M tokens) require more VRAM, increasing costs.
4. How MoE Reduces AI Costs at Scale
4.1 Why MoE is Cheaper to Run
Mixture of Experts (MoE) reduces both training and inference costs by:
- Activating only a fraction of model parameters per query.
- Reducing VRAM and compute requirements significantly.
- Scaling AI efficiently without linear cost growth.
MoE vs. Dense Model Cost Efficiency
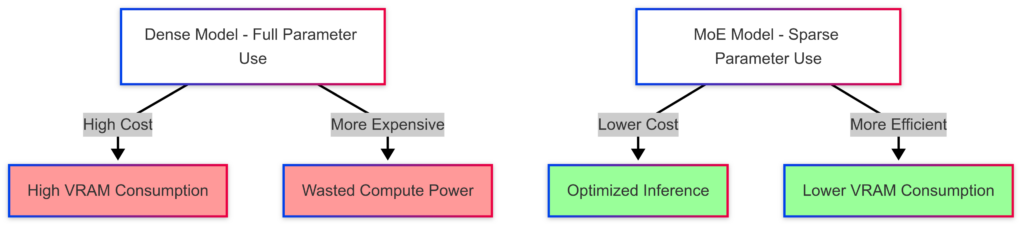
4.2 Practical Challenges of MoE
- Routing Overhead: Selecting the right “experts” introduces some computational complexity.
- Load Balancing: Some experts may become overloaded, leading to inefficiencies.
- Framework Support: PyTorch & TensorFlow are improving MoE support but are still evolving.
5. The Future of AI Cost Efficiency
5.1 AI Compute Decentralization
- AI training is currently centralized within Google, OpenAI, Anthropic, and DeepSeek.
- Decentralized AI models (federated learning, distributed training) could lower barriers for smaller AI startups.
5.2 AI Hardware Innovations
- Nvidia dominates GPUs, but new players like Cerebras, Graphcore, and Tesla’s Dojo AI chips are entering the market.
- AI-specific silicon (e.g., Google’s TPUs) is reducing reliance on generic GPUs.
6. Conclusion: Efficiency Wins the AI Race
AI is no longer about who has the largest model—it’s about who runs AI most efficiently.
✅ MoE-based architectures significantly reduce costs
✅ Custom silicon (TPUs, Dojo chips) optimizes inference
✅ AI decentralization is shaping the future of open-weight AI
“The next great AI revolution won’t be in intelligence—it will be in efficiency.”
— Fei-Fei Li, Stanford AI Researcher
References
- AI Training Cost Breakdown – arxiv.org/abs/ai-training-costs
- MoE Cost Optimization Research – arxiv.org/abs/moe-inference
- AI Hardware Race – carnegieendowment.org/ai-hardware
Related Articles
- AI and Automation
AI in the Workplace: What Jobs AI Can (and Cannot) Take

As AI technology advances, concerns about its impact on jobs rise. While AI can automate routine tasks in sectors like manufacturing and customer service, human skills in creativity, critical thinking, and ethical judgment remain crucial in healthcare, education, and software engineering. The future of work emphasizes collaboration between humans and AI rather than outright replacement.
- AI and Automation
Baidu’s AI Strategy: Ernie 5.0 vs OpenAI & Alibaba – AI’s Next Frontier

Baidu's Ernie 5.0 seeks to challenge OpenAI’s GPT-5 with cutting-edge multimodal AI, lower inference costs, and custom AI chips. But will it claim dominion over China’s AI landscape, or will the tech war with OpenAI and Alibaba prove insurmountable?
- AI and Automation
AI-Powered Endpoint Security: How AI Enhances Threat Detection & Zero Trust

Discover how AI-powered endpoint security enhances threat detection, Zero Trust enforcement, and risk mitigation. Learn how AI-driven automation improves deployment strategies, hybrid security, and predictive analytics to safeguard enterprise endpoints.
Discussion
Loading discussion...