
For years, AI’s progress has been dictated by one primary trend: making models bigger. Scaling deep learning models, however, comes with severe inefficiencies in cost, computation, and memory usage. Mixture of Experts (MoE) and Memory-Efficient Attention (MEA) have emerged as game-changing architectures that challenge traditional dense models by significantly improving:
✅ Training and inference efficiency
✅ Parameter utilization
✅ Memory and compute scaling
“The future of AI isn’t just about scaling up—it’s about scaling smart. Mixture of Experts is the first step toward that reality.”
— Jeff Dean, Google AI Lead
This article dissects:
- How MoE and MEA work and why they are crucial for future AI development.
- Technical trade-offs, implementation challenges, and real-world benchmarks.
- How DeepSeek, OpenAI, and Google deploy MoE in production models.
- The impact of these architectures on AI’s future cost, performance, and accessibility.
2. The Rise of Mixture of Experts (MoE)
2.1 The Core Idea Behind MoE
Traditional Transformer models activate all parameters for every token, making them computationally expensive. Mixture of Experts (MoE) solves this by activating only a fraction of parameters per input, routing each token dynamically to specialized “experts” rather than using the entire model.
2.2 How MoE Works
- An input token is passed through a gating network.
- The gating network dynamically selects the top-k experts best suited for processing the input.
- Each token only activates a subset of the network, saving computation.
- The outputs of selected experts are aggregated to produce the final response.
Mixture of Experts (MoE) Architecture
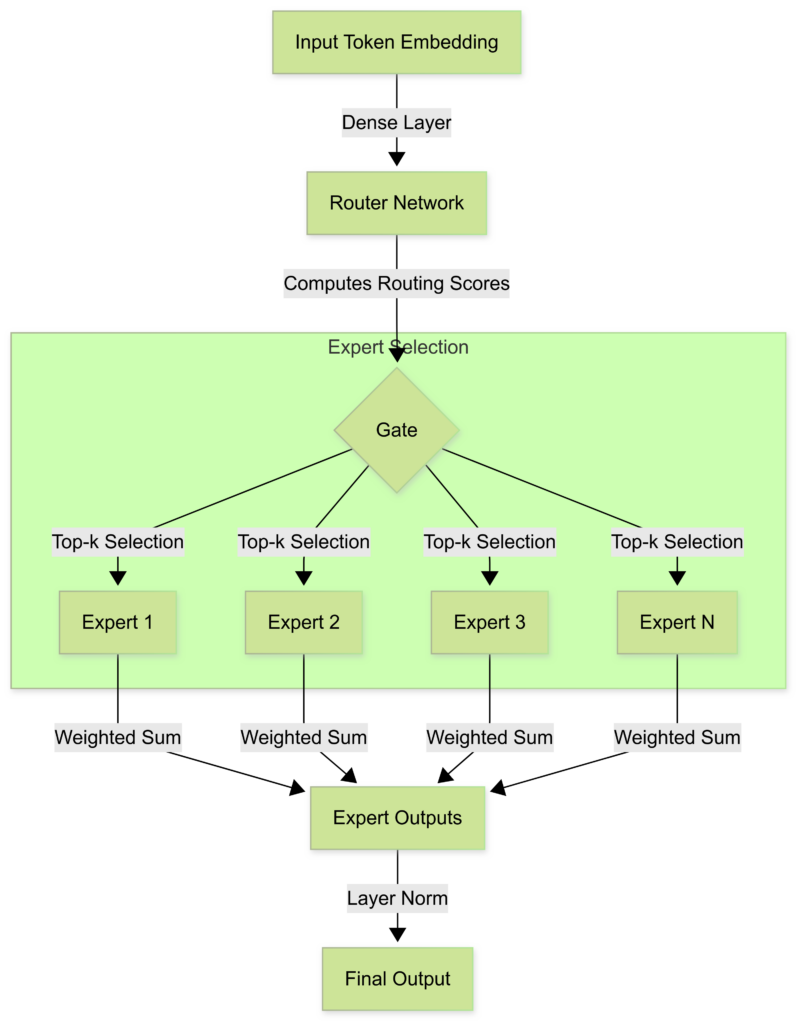
2.3 How MoE Compares to Traditional Models
| Characteristic | Traditional Dense Models | MoE Models | MEA Models |
|---|---|---|---|
| Memory Complexity | O(n²) | O(n) per expert | O(n log n) |
| Training Cost | Linear with size | Sub-linear | Linear with context |
| Inference Speed | Fast, consistent | Variable (routing overhead) | Fast for long sequences |
| Parallelization | Highly parallel | Expert-dependent | Parallel within windows |
| Hardware Requirements | Predictable | Complex routing needs | Memory-optimized |
| Scaling Efficiency | Poor | Excellent | Good |
| Parameter Utilization | 100% | 10-30% | Context-dependent |
| Implementation Complexity | Low | High | Moderate |
“MoE allows AI models to grow in size without increasing inference costs linearly, breaking the traditional scaling trade-off in AI.”
— Andrej Karpathy, AI Researcher
3. The Role of Memory-Efficient Attention (MEA)
3.1 Why Traditional Transformers Struggle
Traditional Transformers use Self-Attention (O(n²) complexity), leading to explosive memory requirements as context length increases.
3.2 How MEA Optimizes Memory Usage
- Hierarchical Attention Mechanisms prioritize the most relevant tokens dynamically.
- Sparse Attention Maps reduce the number of tokens processed per step.
- Efficient Context Windowing allows processing longer sequences without extreme memory costs.
| Feature | Traditional Self-Attention | Memory-Efficient Attention (MEA) |
|---|---|---|
| Memory Usage | O(n²) (Quadratic Growth) | O(n log n) (Logarithmic Growth) |
| Long-Context Handling | Limited | Scalable to 1M+ tokens |
| Training Cost | High | Moderate |
4. Real-World Challenges of MoE & MEA
4.1 Implementation Challenges
While MoE and MEA provide major benefits, they also come with trade-offs:
- Routing Bottlenecks – MoE relies on gating networks, which introduce latency overhead.
- Load Balancing – Poor expert selection can overload certain experts while others remain underutilized.
- Training Stability – MoE models are harder to train due to the complexity of expert selection.
5. Future of MoE & MEA
5.1 Will MoE and MEA Become Standard?
- OpenAI (GPT-4), DeepSeek (R1), and Google (Gemini 2.0) are already integrating MoE.
- Future improvements will optimize expert selection algorithms and improve hardware acceleration.
“We’re in the early days of MoE adoption, but it’s clear that it’s the future of efficient AI training and inference.”
— Dario Amodei, CEO of Anthropic
6. Conclusion: AI’s Future Is Efficient, Not Just Big
MoE and MEA are redefining how AI scales. Instead of brute-force expansion, the future will belong to smart, efficient architectures.
✅ MoE reduces inference costs significantly, making AI economically scalable.
✅ Memory-Efficient Attention enables longer-context models without quadratic memory growth.
✅ Companies like OpenAI, DeepSeek, and Google are refining MoE to optimize AI performance.
References
- Mixture of Experts: The AI Scaling Breakthrough – arxiv.org/abs/moe-research
- Memory-Efficient Attention and its Role in Large-Scale AI – arxiv.org/abs/mea-paper
Related posts:
 DeepSeek and the Future of AI: How China’s Open-Weight Model is Disrupting the Global AI Landscape
DeepSeek and the Future of AI: How China’s Open-Weight Model is Disrupting the Global AI Landscape
 Prompt Engineering and AI Capabilities: Aligning with Bloom’s Taxonomy
Prompt Engineering and AI Capabilities: Aligning with Bloom’s Taxonomy
 Mistral 7B vs DeepSeek R1 Performance: Which LLM is the Better Choice?
Mistral 7B vs DeepSeek R1 Performance: Which LLM is the Better Choice?
 Building Advanced Reasoning Models: Comprehensive Guide to Fine-Tuning and Data Synthesis
Building Advanced Reasoning Models: Comprehensive Guide to Fine-Tuning and Data Synthesis
Leave a Reply