Google’s database strategy is transforming the way enterprises leverage AI. By embedding vector processing capabilities into existing databases such as Spanner, AlloyDB, and Cloud SQL, Google eliminates the need for standalone vector databases. This innovative approach ensures scalability, enhances performance, and reduces complexity, enabling businesses to harness AI without disrupting their existing infrastructure.
The Vector Database Debate: Integration Over Specialization
Google’s decision to enhance existing databases like PostgreSQL, MySQL, and Spanner with vector processing capabilities is a game-changer. Unlike competitors who build standalone vector databases, Google brings AI capabilities to where enterprise data already resides.
Key Advantages of Integration:
- No Data Migration: Reduces cost, latency, and security risks by eliminating the need to duplicate data into specialized databases.
- Seamless Security: Leverages existing enterprise-grade database security frameworks.
- Developer Efficiency: Provides vector processing, natural language interfaces, and AI integration directly in familiar tools.
For example, embedding AI capabilities into Spanner allows enterprises to run similarity searches or retrieval-augmented generation (RAG) workflows without complex data transfers.
Example of Vector Search Query:
With vector indexing embedded in databases, similarity searches become straightforward:
SELECT *
FROM bigquery_project.dataset.table
JOIN spanner_project.database.table
ON bigquery_table.id = spanner_table.id
WHERE spanner_table.vector_similarity > 0.8;This query finds the most relevant documents by comparing their vector embeddings to a given query vector.
Federated Queries: Unified Data Access
Google’s BigQuery Federation enables querying across multiple data sources (e.g., Spanner, Cloud SQL) without data migration.
Example of Federated Query:
SELECT document_id, similarity_score
FROM vector_index
ORDER BY similarity(vector_embedding, query_vector) DESC
LIMIT 10;This capability allows developers to seamlessly integrate operational and analytical data for AI workflows.
Integrating Databases with Vertex AI
Google’s Vertex AI simplifies deploying AI models while leveraging enterprise data.
Code Snippet: Querying a Database for AI Integration
from google.cloud import spanner
from vertexai.language_models import TextGenerationModel
# Connect to Spanner
spanner_client = spanner.Client()
database = spanner_client.instance('instance-id').database('database-id')
# Query Spanner
with database.snapshot() as snapshot:
query = 'SELECT text_column FROM my_table WHERE vector_score > 0.9'
results = snapshot.execute_sql(query)
# Pass results to AI model
model = TextGenerationModel.from_pretrained('gemini-large')
for row in results:
response = model.predict(row[0])
print(response.text)This example shows how enterprise data from Spanner can directly interact with AI models hosted on Vertex AI.
Unmatched Scale and Performance: Google’s Infrastructure Advantage
Google’s databases operate at a scale unparalleled in the industry, with Spanner leading the charge.
Performance Metrics:
- 4 Billion Queries Per Second: Spanner processes this staggering volume, far outpacing competitors like Amazon Prime Day’s peak traffic of ~200 million QPS.
- Global Networking Infrastructure:
- 2 Million Miles of terrestrial and subsea cables (10x more than competitors).
- TPU and GPU integration optimized for AI workloads.
- Petabyte-Scale Databases: Systems like BigTable handle over 100 petabytes, ready for the data demands of AI.
Google’s ability to leverage internal innovations—like the TPU infrastructure powering YouTube, Search, and Gmail—ensures enterprise customers benefit from proven, scalable technology.
Cost Savings:
Google’s sub-linear infrastructure growth ensures that even as workloads increase, cost efficiency is maintained. For example:
- AI-powered vector queries integrated into Spanner saved a retail customer 30% in data processing costs.
- Consolidating analytical and operational databases reduced infrastructure costs by 20% for a financial services client.
Architecture: AI-Enabled Database Ecosystem
Google’s architecture integrates traditional databases with AI components to ensure scalability, security, and seamless data flow.
Data Flow Diagram:
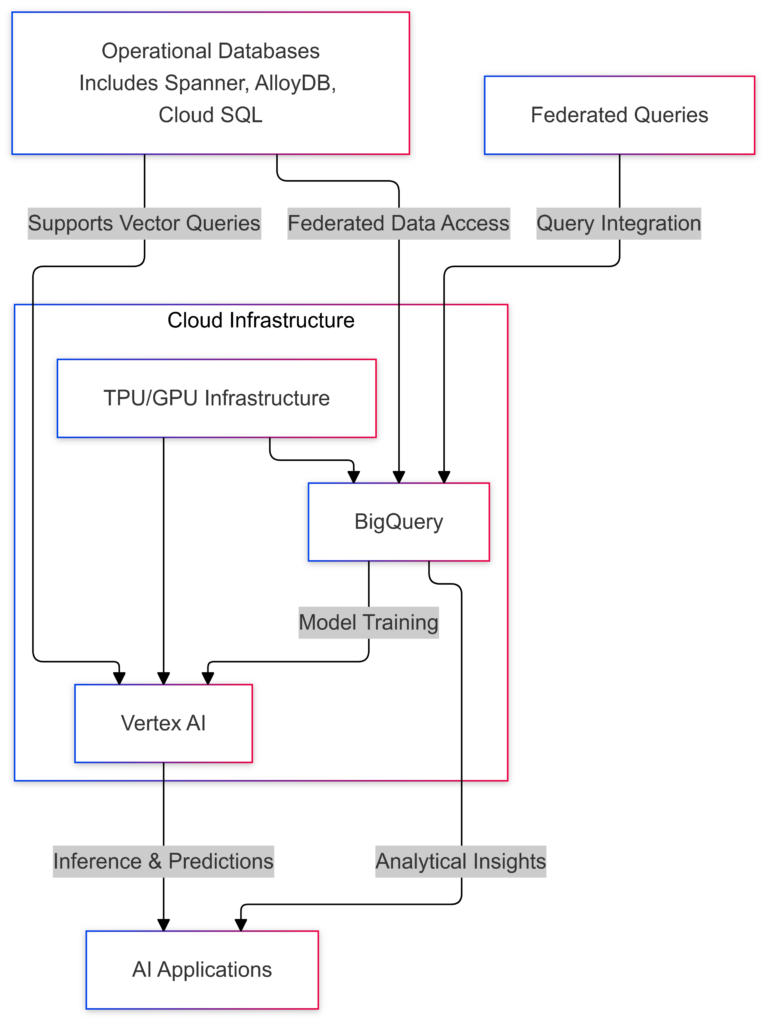
- Operational Databases (e.g., Spanner, MySQL):
- Store and process real-time transactional data.
- Serve as the primary source for vector indexing and similarity searches.
- BigQuery:
- Acts as an analytical layer for large-scale data processing.
- Supports federated queries to operational databases.
- Vertex AI:
- Consumes data from databases for model training and inferencing.
- Offers built-in connectors for direct database interaction.
Security Architecture:
- Access Controls:
- Granular role-based access for querying and AI model integration.
- Workload Isolation:
- Separate compute resources for training and inferencing to prevent interference.
- End-to-End Encryption:
- Ensures data integrity across all components in the AI pipeline.
Business Impact: Driving Developer Productivity and ROI
Google’s integrated approach empowers developers and delivers measurable business value.
Key Success Metrics:
- Developer Empowerment: Every developer can now implement AI-driven features without deep expertise.
- Improved ROI:
- A global logistics company reduced data latency by 50%, enabling faster AI-powered decision-making.
- An e-commerce platform increased conversion rates by 15% using AI-enhanced product recommendations.
Use Case: Retail Personalization:
A retailer leveraged vector search in Spanner for personalized product recommendations:
- Query runtime: Reduced by 60% compared to legacy systems.
- Customer satisfaction: Increased by 20%, as measured by repeat purchases.
Future Trends and Challenges
Predicted Developments:
- Improved Unstructured Data Handling:
- Enhanced support for multimedia AI applications (video, audio, images).
- Developer Interfaces:
- Simplified tools for building multimodal AI workflows.
- Increased Scalability:
- Preparing for exabyte-scale workloads.
Challenges:
- Data Governance: As querying becomes more unstructured, maintaining compliance and security will remain critical.
- Competitive Pressure: Competitors like AWS and Databricks focus on specialized tools, challenging Google’s integrated approach.
Conclusion
Google’s database strategy highlights the transformative potential of integrating AI capabilities into existing systems. By focusing on scalability, cost efficiency, and developer accessibility, Google is equipping enterprises to leverage AI without disrupting their infrastructure. Explore how Google Cloud’s database solutions can enhance your AI strategy. Visit Google Cloud Databases and start building smarter, AI-enabled systems today.




Leave a Reply