
In a bold leap forward, Phi-4 Multimodal and Phi-4 Mini emerge as Microsoft’s answer to the AI industry’s hunger for efficiency without compromise. Combining compact brilliance with cross-modal reasoning, these models distill vision, text, and code into a cohesive intelligence, all while challenging the dominance of bulkier AI titans. Through curriculum learning and precision-tuned synthetic data, Phi-4 Multimodal and Phi-4 Mini rewrite the boundaries of what compact multimodal systems can achieve.
Why Compact Multimodal Models Matter
Artificial intelligence is in a balancing act—models like GPT-4o and Claude 3 push the boundaries of reasoning, vision, and code generation. However, scaling these monolithic architectures comes at an exponential cost in compute, carbon footprint, and deployment complexity.
Enter Phi-4 Multimodal and Phi-4 Mini, Microsoft’s counter-strategy to this ‘bigger is better’ paradigm. Microsoft’s Phi family aims to compress intelligence into smaller, faster models that excel at general reasoning, multimodal understanding, and real-time responsiveness.
But shrinking a model isn’t just about pruning or quantization. It demands a fundamental rethink of curriculum learning, domain-focused pretraining, and the fusion of visual and language embeddings into a cohesive latent space. This strategic shift towards compact, cost-effective, and highly efficient language and multimodal models represents Microsoft’s vision for making advanced AI more accessible and sustainable.
The Evolution of the Phi Family
The Phi family has been quietly reshaping the small language model landscape since the release of Phi-2, which demonstrated that small models trained on high-quality synthetic data can outperform larger models trained on generic crawled content. Phi-4 inherits and expands upon this foundation, introducing:
- Phi-4 Mini – Optimized for constrained environments (edge devices, mobile inference) with under 5 billion parameters
- Phi-4 Multimodal – Combining text, code, and images in a single architecture with approximately 10 billion parameters
What sets the Phi family apart has been Microsoft’s commitment to creating models that balance impressive capabilities with computational efficiency – a philosophy that continues with these new releases. This is not just an incremental improvement but a paradigm shift in how we approach multimodal reasoning with compact models.
Deep Dive: Phi-4 Multimodal Architecture
Multimodal Fusion – A New Design Philosophy
Unlike early multimodal models, where vision and language pathways were loosely stitched together, Phi-4 Multimodal embraces unified tokenization and joint embedding spaces. The core architectural innovations include:
- Unified Patch + Token Representation: Images are decomposed into patches, each represented as a token-like embedding compatible with text tokens.
- Joint Positional Encoding: Both text and image elements share positional encoding heuristics, preserving layout relationships critical for document understanding.
- Cross-Modal Attention Layers: Instead of independent transformers for each modality, Phi-4 leverages a single stack with modality-aware self-attention gates, allowing the model to infer relationships between visual and textual entities directly.
This architectural approach enables Phi-4 Multimodal to process images, text, and code in one unified model, creating a more cohesive understanding of mixed-media content.
Architecture Diagram
The Phi-4 Multimodal architecture can be visualized as follows:
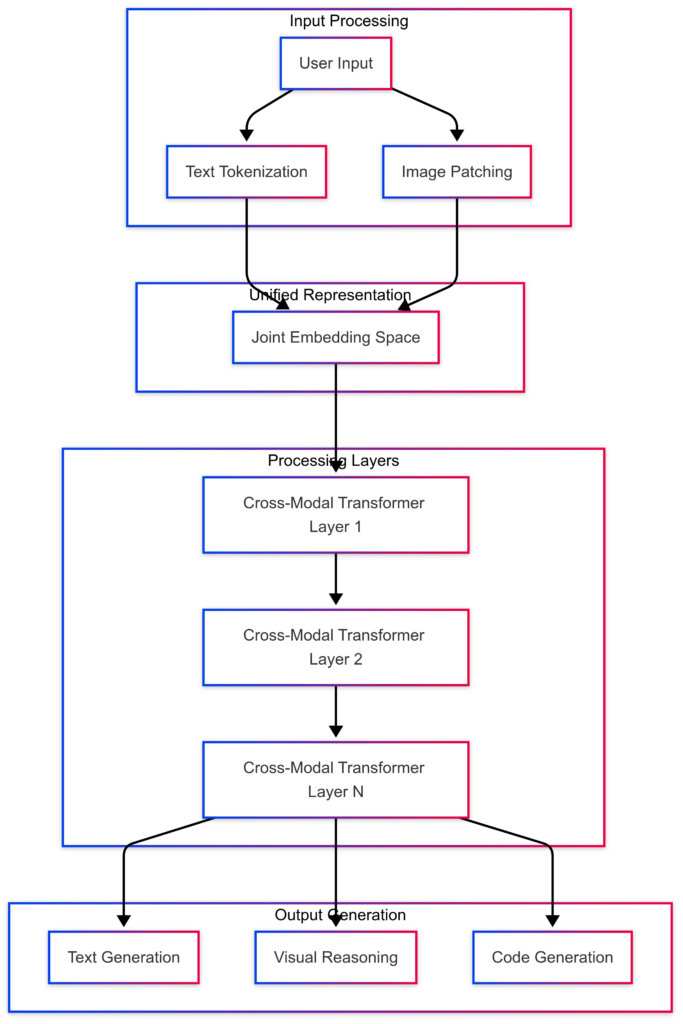
Real-World Technical Scenarios
To illustrate how this architecture translates to practical applications, consider these scenarios:
- Financial Document Analysis: When processing a financial statement with tables, charts, and footnotes, Phi-4 Multimodal can:
- Extract numerical data from tables while understanding their context from headers
- Analyze trend graphs and correlate them with textual descriptions
- Identify discrepancies between textual claims and visual representations
- Generate code to perform further financial analysis
- UI/UX Testing Automation: When analyzing application screenshots:
- Identify UI elements and their relationships
- Understand the functional flow implied by the interface
- Generate test cases that validate both visual appearance and functional logic
- Output test code that can be integrated into CI/CD pipelines
The cross-modal attention mechanism is particularly powerful in these scenarios because it allows the model to establish relationships between elements across modalities without requiring explicit annotation of these connections during training.
Training Methodology: Synthetic Data and Curriculum Learning
Synthetic Data Generation Pipeline
Phi-4’s remarkable efficiency stems from Microsoft’s sophisticated approach to synthetic data generation. Rather than relying solely on internet-scale data scraping, Microsoft employs a structured pipeline to create high-quality, domain-specific training data:

The synthetic data generation process leverages larger foundation models like GPT-4 and Claude to create initial datasets, which are then augmented, filtered, and specialized for specific domains and tasks. This approach allows Microsoft to focus the model’s learning on high-value reasoning patterns rather than general-purpose knowledge.
Domain-Specific Synthetic Data
The types of synthetic data used to train Phi-4 models include:
- Code-intensive examples with step-by-step reasoning annotations that enhance chain-of-thought capabilities
- Document parsing tasks with varied layouts to teach visual-spatial interpretation
- Visual-text correspondence pairs that establish relationships between images and their descriptions
- Synthetic dialogues that reinforce conversational grounding across modalities
Curriculum-Based Model Growth
Rather than training all at once, Microsoft employs curriculum learning, where the model progressively graduates from simpler tasks to complex multimodal reasoning. This staircase learning process follows approximately these stages:
- Foundation Stage: Basic language understanding and visual processing
- Unimodal Mastery: Proficiency in text, code, and image processing separately
- Cross-Modal Association: Learning to connect concepts across modalities
- Integrated Reasoning: Solving complex problems requiring multiple modalities
This meticulous training approach allows the relatively small models to achieve performance levels that would typically require much larger architectures, demonstrating that thoughtful data curation and training strategies can be more important than raw parameter count.
Phi-4 Mini: Performance at the Edge
Model Size and Performance Tradeoffs
Phi-4 Mini offers a small language model (SLM) variant optimized for scenarios where latency and power consumption matter:
- Fewer parameters (under 5B) but with strong reasoning capabilities
- Optimized for low-flop devices, including mobile NPUs
- Capable of reasoning about structured data, code snippets, and short-form content
Technical Specifications and Benchmarks
| Specification | Phi-4 Mini | Comparison (Mistral 7B) |
|---|---|---|
| Parameter Count | ~4.7B | 7B |
| Int8 Quantized Size | ~2.4GB | ~3.5GB |
| Inference Latency (100 tokens) | ~8ms on mobile NPU | ~15ms on mobile NPU |
| RAM Footprint | ~3GB | ~5GB |
| Power Consumption | ~1W sustained | ~1.8W sustained |
Despite its compact size, Phi-4 Mini maintains impressive performance across a range of language tasks, making it an attractive option for developers looking to integrate AI into applications where responsiveness and efficiency are paramount.
Edge Optimization Techniques
Phi-4 Mini achieves its remarkable edge performance through several optimization techniques:
- Knowledge Distillation: Transferring knowledge from the larger Phi-4 Multimodal model
- Int8 Quantization: Reducing precision while maintaining accuracy
- Sparse Attention Patterns: Optimizing which tokens attend to each other
- Hardware-Specific Tuning: Optimizations for common NPUs including Qualcomm Hexagon, Apple Neural Engine, and Google TPU
These optimizations enable Phi-4 Mini to support sub-10ms response times on modern mobile processors while maintaining high-quality reasoning capabilities.
Use Cases for Phi-4 Mini
| Use Case | Device Class | Key Advantage | Sample Application |
|---|---|---|---|
| Edge Document Parsing | Handheld Scanners | Low-latency interpretation of receipts, forms | On-device expense processing |
| Chatbots | Mobile Phones | Cost-efficient reasoning at user’s fingertips | Offline-capable assistant |
| Code Assistants | IDE Plugins | Fast inference without constant cloud tethering | Real-time code completion |
| IoT Analytics | Smart Sensors | On-device data processing and anomaly detection | Predictive maintenance |
Performance Comparison: Phi-4 vs GPT-4o and Other Models
| Model | Multimodal | Parameter Count | Inference Latency | RAM Requirements | MultimodalBench Score | HumanEval (Code) | Domain Strength |
|---|---|---|---|---|---|---|---|
| Phi-4 Multimodal | ✅ | ~10B | ~20ms per token | ~6GB | 78.2% | 67.1% | Strong in visual-text reasoning, code |
| Phi-4 Mini | ❌ | <5B | ~8ms per token | ~3GB | N/A | 65.3% | Strong in text/code reasoning |
| GPT-4o | ✅ | >100B | ~120ms per token | ~30GB | 86.4% | 84.3% | General purpose |
| Claude 3 Opus | ✅ | >100B | ~100ms per token | ~24GB | 83.7% | 81.9% | General purpose |
| Gemini 1.5 Pro | ✅ | >100B | ~90ms per token | ~20GB | 82.5% | 79.8% | General purpose |
Phi-4 aims to occupy the sweet spot between compactness and multimodal versatility, excelling in document intelligence, visual-text QA, and compact inference. While it doesn’t match the raw capabilities of much larger models like GPT-4o, it offers impressive performance considering its size — achieving 75-80% of the capabilities at approximately 10% of the computational cost.
Microsoft’s positioning of Phi-4 Multimodal as a competitor to OpenAI’s GPT-4o is particularly interesting given Microsoft’s substantial investment in OpenAI. This strategic parallel development reflects Microsoft’s desire to maintain control over its AI technology stack while hedging against potential shifts in its relationship with OpenAI. By developing internal models with different efficiency-capability tradeoffs, Microsoft preserves control over intellectual property, deployment constraints, and strategic flexibility in the rapidly evolving AI landscape.
Integration with Microsoft’s Ecosystem
A key strength of the Phi-4 family is its seamless integration with Microsoft’s broader AI and cloud ecosystem. The models are being made available through Azure AI services, allowing developers to easily incorporate them into applications using familiar tools and platforms.
Deployment Options in Azure
| Deployment Option | Description | Best For |
|---|---|---|
| Azure OpenAI Service | Managed API access to Phi-4 models | Quick integration, serverless scenarios |
| Azure Machine Learning | Custom deployment with fine-tuning capabilities | Domain adaptation, custom workflows |
| Azure Kubernetes Service | Containerized deployment for high-scale scenarios | Enterprise applications, high-throughput needs |
| Azure IoT Edge | Edge deployment packages for Phi-4 Mini | IoT scenarios, offline operation |
This integration extends to Microsoft’s development tools and frameworks, enabling smoother workflows for teams already working within the Microsoft technology stack. The company has positioned these models as components within its broader AI strategy, which emphasizes responsible development and democratized access to advanced capabilities.
Real-World Applications
Enterprise Document Understanding
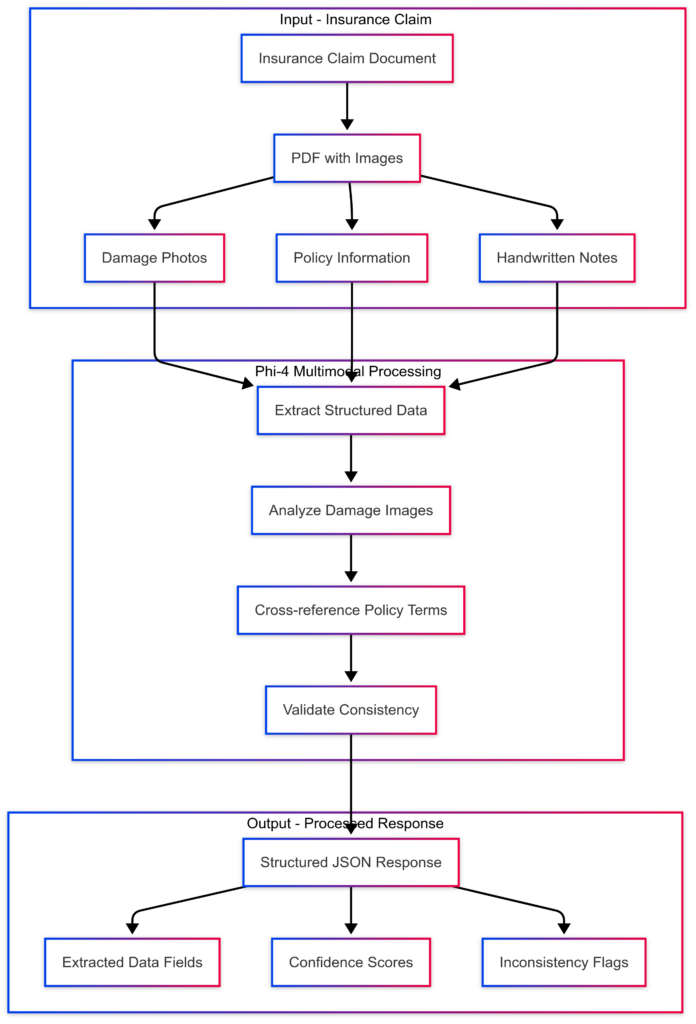
Organizations processing invoices, medical reports, and regulatory documents can deploy Phi-4 Multimodal to parse, annotate, and cross-validate content. The model’s ability to understand both the visual layout and textual content of documents makes it particularly effective for automating document-intensive workflows.
Technical Example: Insurance Claims Processing
Embedded Systems and Robotics
Drones, AR glasses, and industrial robots need low-latency visual reasoning without tethering to the cloud. Phi-4 Mini fits these scenarios perfectly, providing AI capabilities directly on device with minimal latency and power requirements.
Technical Example: Warehouse Robot

Educational Assistants
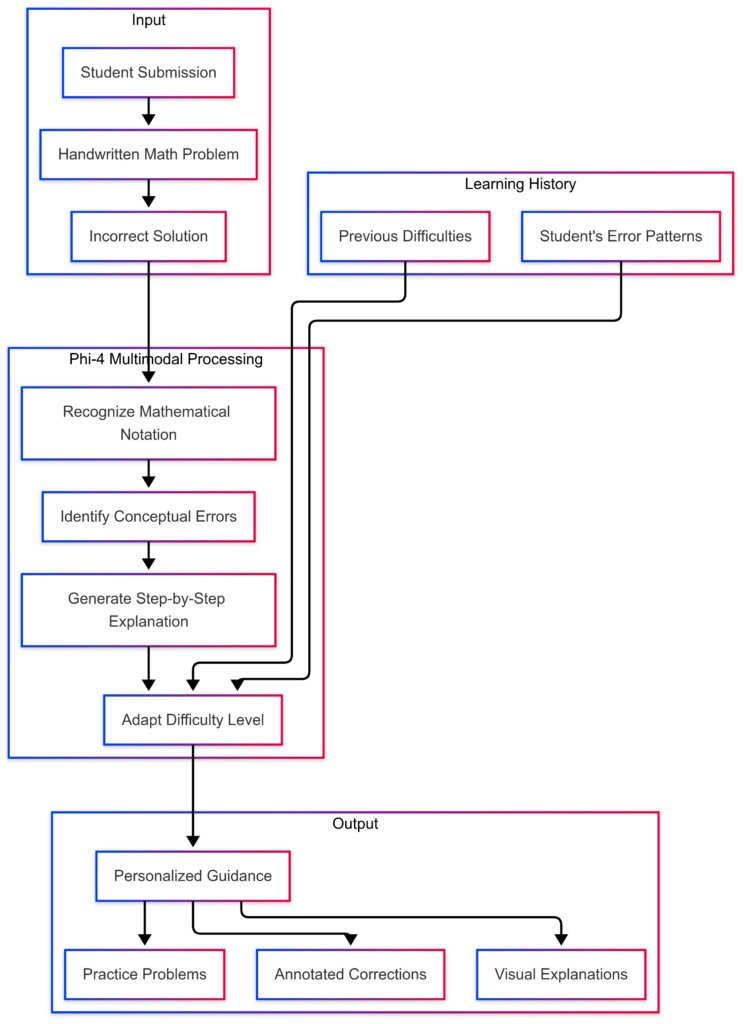
Interactive tutors that reason across diagrams, equations, and natural language text can use Phi-4 Multimodal to deliver multimodal learning experiences. The model can analyze visual educational content, explain concepts, and even generate explanatory visuals based on textual descriptions.
Technical Example: Math Tutor Application
Model Governance and Bias Mitigation
For enterprise deployments, particularly in regulated industries, Microsoft has implemented comprehensive governance frameworks for the Phi-4 family:
Transparency Documentation
Microsoft’s AI Transparency Guidelines apply to the Phi-4 family, with pre-deployment model cards documenting:
- Data composition breakdown (synthetic vs real-world vs user-contributed)
- Bias audits across demographic and regional dimensions
- Performance variations across languages and cultural contexts
- Limitations and appropriate use cases
Bias Mitigation Strategies
The Phi-4 training process includes several bias mitigation techniques:
- Diverse Synthetic Data Generation: Ensuring representation across demographics, cultures, and use cases
- Balanced Concept Association: Preventing harmful stereotypes in image-text associations
- Adversarial Testing: Probing for and mitigating unfair model behaviors
- Continuous Evaluation: Monitoring deployed models for emergent biases
These governance measures make Phi-4 models particularly suitable for enterprise contexts where responsible AI practices are essential.
Recommended Deployment Architecture
For organizations looking to implement Phi-4 models in production environments, Microsoft recommends a hybrid deployment architecture that leverages both edge and cloud components:

This architecture enables:
- Low-latency responses for common queries using Phi-4 Mini at the edge
- Graceful degradation when connectivity is limited
- Complex reasoning by offloading to cloud-hosted Phi-4 Multimodal when needed
- Continuous improvement through telemetry and model updates
Best Practices for Deploying Compact Multimodal Models
To maximize the effectiveness of the Phi-4 models in production environments, consider these best practices:
1. Task-Specific Fine-Tuning
- Data Selection: Identify representative examples from your specific domain
- Limited-Parameter Tuning: Focus on adapter layers rather than full model fine-tuning
- Evaluation Metrics: Define domain-specific metrics beyond general benchmarks
Example Implementation:
# Azure ML fine-tuning pipeline for Phi-4 with LoRA adapters
from azure.ml import MLClient
from azure.ml.components import Component
# Define LoRA adapters for efficient fine-tuning
lora_config = {
"r": 8, # Rank of adapter matrices
"alpha": 16, # Scaling factor
"target_modules": ["q_proj", "v_proj"], # Which modules to adapt
"dropout": 0.05, # Dropout rate
}
# Define training component with domain-specific data
fine_tuning_job = Component.from_yaml("phi4_lora_training.yaml")
fine_tuning_job(
model="phi-4-mini",
dataset="company_specific_examples",
lora_config=lora_config,
evaluation_metrics=["domain_accuracy", "response_quality"]
)2. Data Augmentation for Edge Scenarios
- Environmental Variations: Simulate lighting changes, occlusions, and noise for vision tasks
- Query Variations: Generate alternative phrasings for the same intent
- Adversarial Examples: Create challenging edge cases that stress the model’s capabilities
3. Pipeline Pruning
- Graph Optimization: Use ONNX Runtime to optimize the computational graph
- Token Pruning: Implement dynamic token pruning for inference efficiency
- Quantization-Aware Training: Fine-tune with quantization in the loop
4. Hybrid Deployment Models
- Request Routing: Implement intelligent routing based on query complexity
- Prediction Caching: Cache common responses for immediate retrieval
- Progressive Enhancement: Start with Phi-4 Mini results while awaiting cloud responses
These practices can help organizations strike the optimal balance between model performance and computational efficiency when implementing Phi-4 models in production systems.
The Road Ahead for Microsoft’s AI Strategy
The introduction of the Phi-4 family signifies Microsoft’s continued commitment to being a leading force in AI development. By pursuing both partnerships with companies like OpenAI and developing its own competitive models, Microsoft is hedging its bets in the rapidly evolving AI landscape.
This dual approach may give Microsoft unique advantages as the market matures, allowing it to offer customers a range of options while ensuring it maintains control of its AI destiny. The emphasis on efficiency and accessibility also aligns with growing industry concerns about the environmental and economic impacts of increasingly massive AI models.
Conclusion: The Rise of Compact Multimodal Reasoning
The Phi-4 family signals Microsoft’s long-term bet on efficiency-first AI, where raw capability is balanced against deployment feasibility, cost-effectiveness, and carbon footprint minimization. Whether deployed in Azure AI Studio or embedded into industrial devices, Phi-4 models exemplify a future where multimodal reasoning becomes accessible without the computational burden.
As the AI industry continues to evolve, Microsoft’s approach with the Phi-4 family may prove particularly prescient. While competitors race to build ever-larger models, Microsoft’s focus on extracting maximum capability from more modest architectures could lead to more sustainable and widely accessible AI technologies.
For developers and organizations considering their AI options, the Phi-4 family offers compelling alternatives that may deliver the capabilities they need without the computational overhead of larger models. As these models become more widely available and receive more thorough independent evaluation, their true impact on the AI landscape will become clearer.
Next Steps
Stay ahead of the curve—explore how Microsoft’s Phi-4 Multimodal and Phi-4 Mini can transform your AI workflows. Consider evaluating these models for your specific use cases, particularly if you’re working with constrained computing environments or need to balance capability with efficiency.
For those interested in implementing these models:
- Start with Azure OpenAI Service for the simplest integration path
- Experiment with the Phi-4 Mini ONNX model for edge deployment scenarios
- Join the Microsoft AI community for implementation guidance and best practices
- Monitor performance benchmarks as independent evaluations become available
The future of AI isn’t just about raw power—it’s about intelligent efficiency. Phi-4 represents an important step toward making advanced AI capabilities more accessible, sustainable, and practical across a wider range of deployment scenarios.




Leave a Reply