
The DeepSeek-R1 Architecture and Training Process demonstrates how cutting-edge AI models can achieve high reasoning capabilities with cost efficiency. This article takes a deep dive into DeepSeek-R1’s Mixture of Experts (MoE) architecture, explaining its expert routing, parallelization strategy, and model specialization. We also break down its reinforcement learning-based training, covering reward mechanisms, data processing, and optimization techniques that enhance logical reasoning and efficiency. Whether you’re an AI researcher, developer, or enthusiast, this guide provides an in-depth understanding of how DeepSeek-R1 was built and why it stands out in the AI landscape.
2. Architecture Deep Dive
DeepSeek-R1 is a text-generation AI model designed for complex reasoning and logical inference. It is based on a Mixture of Experts (MoE) architecture, which allows it to dynamically allocate computational resources to different specialized components.
2.1 Mixture of Experts (MoE) Architecture
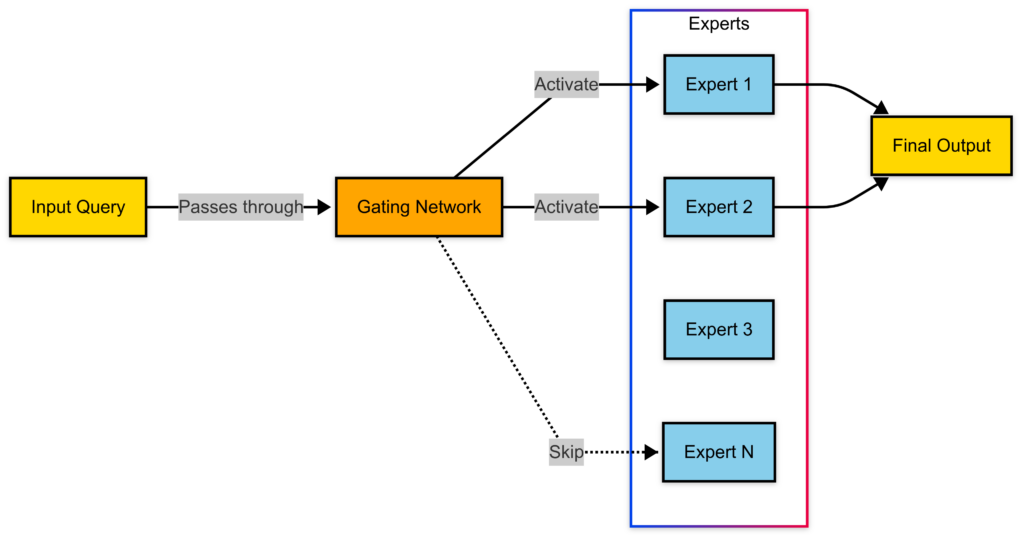
DeepSeek-R1’s architecture leverages an MoE framework where multiple expert networks process different parts of an input, with only a subset of experts activated per query.
- Total Parameters: 671B, but only 37B active per inference step.
- Expert Networks: Multiple specialized networks trained on different domains of knowledge.
- Routing Mechanism: A gating network decides which experts to activate per query, optimizing efficiency.
2.2 Expert Selection and Routing Algorithm
During inference, DeepSeek-R1 uses a learned routing mechanism that efficiently selects relevant experts based on input context.
- Step 1: The input is passed through a lightweight gating network that assigns a probability distribution over all experts.
- Step 2: The model selects a subset of the highest-ranked experts (typically 2-4 per query).
- Step 3: Selected experts process the query in parallel, producing intermediate representations.
- Step 4: Outputs from experts are aggregated through a weighted sum mechanism, forming the final response.
2.3 Parallelization Strategy
To optimize performance and scalability, DeepSeek-R1 employs distributed training techniques:
- Model Parallelism: Large layers are split across multiple GPUs to handle extensive computation.
- Data Parallelism: Training data is distributed across GPUs, allowing synchronized updates to parameters.
- Pipeline Parallelism: Different model components are processed simultaneously, reducing latency.
3. Training Process: Reinforcement Learning at Scale
DeepSeek-R1’s training methodology departs from traditional supervised learning and instead focuses on reinforcement learning (RL) for reasoning. This strategy allows the model to improve its logical consistency and adaptability without requiring large-scale human annotations.
3.1 Data Preparation
The model’s training corpus includes:
- Filtered Web Data: Pre-cleaned, high-quality textual data.
- Domain-Specific Knowledge: Mathematical, scientific, and reasoning datasets.
- Self-Generated Feedback Data: AI-generated responses evaluated and curated for self-improvement.
3.2 Pre-training Strategy
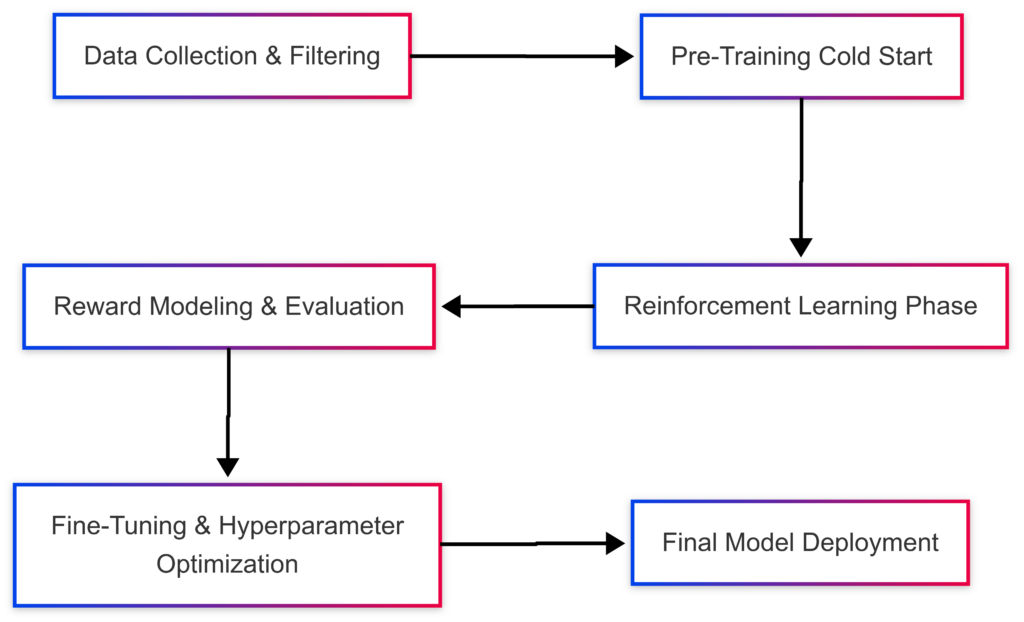
Initial training follows a two-phase approach:
- Cold Start Phase (2 weeks):
- Basic language comprehension training.
- Minimal supervised fine-tuning (~1% of standard approaches).
- Reinforcement Learning Phase (8 weeks):
- Self-improvement through trial and error.
- Adaptation of reasoning strategies.
3.3 Reinforcement Learning Implementation
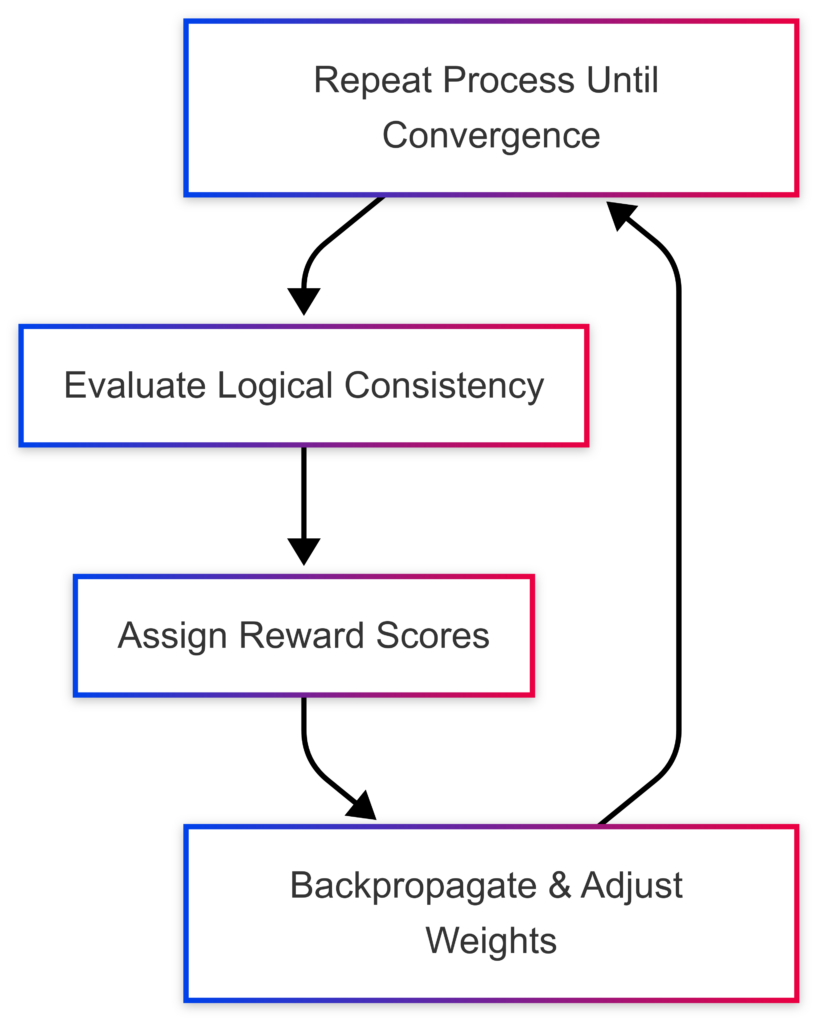
DeepSeek-R1 utilizes reward modeling and reinforcement learning to fine-tune its reasoning abilities.
- Step 1: Generate multiple outputs for a given query.
- Step 2: Evaluate outputs based on logical consistency and correctness.
- Step 3: Assign reward values to different response structures.
- Step 4: Train the model using reinforcement learning to favor high-reward outputs.
Reward Calculation Algorithm
def calculate_reward(response):
rewards = {
'logical_consistency': score_logic(response),
'solution_accuracy': verify_solution(response),
'reasoning_clarity': evaluate_clarity(response),
'efficiency': measure_step_efficiency(response)
}
final_reward = (
0.4 * rewards['logical_consistency'] +
0.3 * rewards['solution_accuracy'] +
0.2 * rewards['reasoning_clarity'] +
0.1 * rewards['efficiency']
)
return final_reward3.4 Optimization Techniques
To improve training efficiency, DeepSeek-R1 incorporates:
- Gradient Checkpointing: Reduces memory consumption by recomputing intermediate values.
- Mixed Precision Training: Uses FP16 precision to optimize GPU memory usage.
- Layer-wise Adaptive Learning Rates: Fine-tunes different layers at varying rates to enhance convergence speed.
4. Results and Validation
4.1 Training Metrics
| Training Phase | Duration | Compute Usage | Quality Threshold |
|---|---|---|---|
| Cold Start | 2 weeks | 15% | 0.75 |
| RL Training | 8 weeks | 70% | 0.85 |
| Rejection Sampling | 4 weeks | 15% | 0.90 |
4.2 Benchmark Performance
DeepSeek-R1 is evaluated against industry-leading AI models.
| Benchmark | DeepSeek-R1 Score | GPT-4 Score |
| MATH-500 | 97.3% | 98.2% |
| ARC Reasoning | 88.5% | 90.1% |
| GSM8K (Math) | 82.7% | 85.5% |
4.3 Cost Efficiency Analysis
| Factor | DeepSeek-R1 | GPT-4 |
| Training Cost | ~$5.58M | ~$100M+ |
| Active Parameters | 37B | 1.8T |
| Hardware Requirement | Consumer GPUs | High-end clusters |
5. Appendix: Deployment and System Requirements
5.1 System Requirements
| Component | Minimum | Recommended |
| GPU | RTX 3060 | RTX 4080+ |
| RAM | 16GB | 32GB+ |
| Storage | 50GB SSD | 100GB+ SSD |
5.2 Community Resources
DeepSeek-AI offers various resources for developers:
6. Key Takeaways
✔ Innovative Mixture of Experts (MoE) architecture optimizes inference efficiency.
✔ Reinforcement learning enhances reasoning and adaptability.
✔ Cost-efficient model training with reduced compute needs.
✔ Competitive performance against GPT-4 in multiple benchmarks.
Related posts:
 OpenAI o3-mini Reasoning Model vs DeepSeek R1: A Response to the Open-Source Challenge
OpenAI o3-mini Reasoning Model vs DeepSeek R1: A Response to the Open-Source Challenge
 Build a Custom AI Coding Chatbot with DeepSeek API & Ollama: Free GitHub Copilot Alternative
Build a Custom AI Coding Chatbot with DeepSeek API & Ollama: Free GitHub Copilot Alternative
 The Future of Drug Testing: How Organs-on-Chips are Redefining Biomedical Research
The Future of Drug Testing: How Organs-on-Chips are Redefining Biomedical Research
 AI Agents and Browser Automation: The Coming Disruption of Internet Economics
AI Agents and Browser Automation: The Coming Disruption of Internet Economics
Leave a Reply